AI とはじめる開発リハビリ(1)
ということで、AI たち(主に ChatGPT)と一緒に開発のリハビリとして何でも作っていきます。
↓前回の記事はこちら↓
今回は、OpenAI の Audio API の Text To Speech (TTS) が気になったので、「OpenAI TTS API の6種類の音声を好きな入力文で試せる UI を Jupyter Notebook で」作ります。
準備
準備したものを、以下にサクッと簡単にまとめます。
- Docker 環境
- Jupyter 環境を用意する
pip install openaiもしておく- OpenAI の API Key を発行する
- ChatGPT Plus を契約(この記事では ChatGPT-4 を使うため)
まずは考える
ここでいきなり ChatGPT に投げたほうが人間を辞め易いのでしょうが、まだその境地まで至れていないので、まずは頭の中でボヤッとどんな感じにするかを考えます。
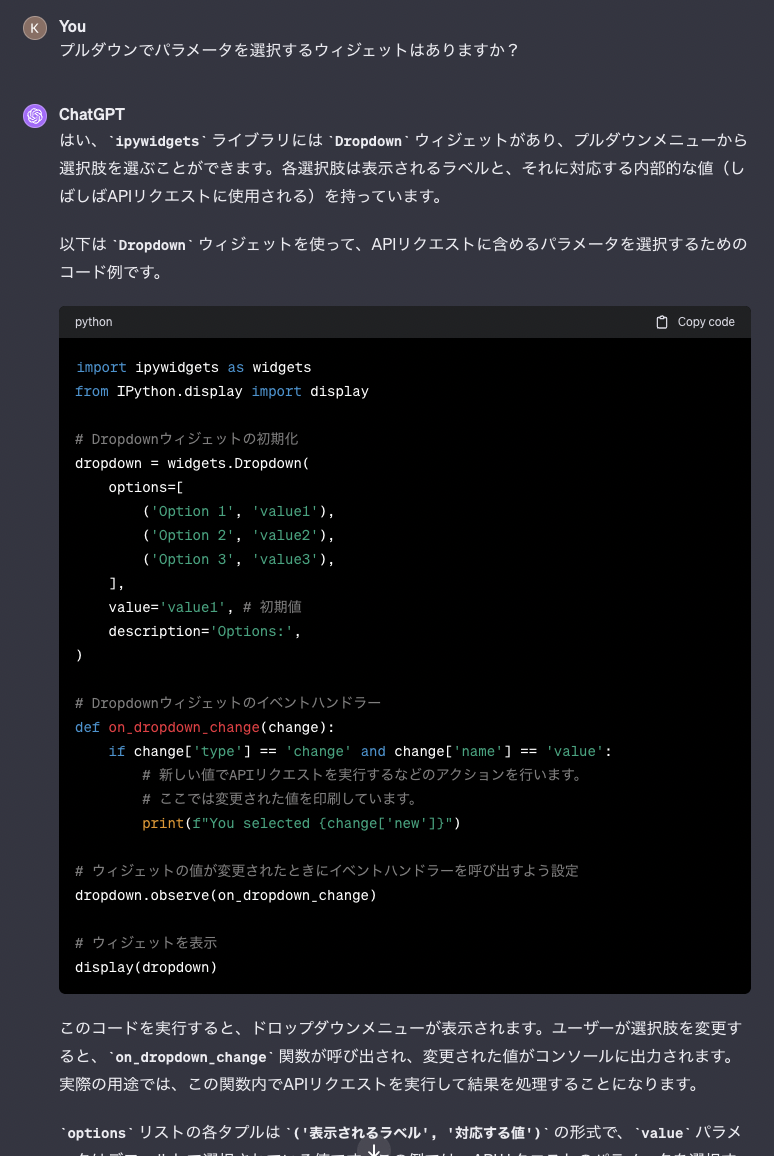
- Voice をプルダウンで選択
- テキストを入力する
- その他パラメータがあれば入力できるようにしておく
- submit ボタンを押すと API にリクエストを投げる
- 帰ってきた音声データをプレイヤーにロードして表示
これでいけそうだけど、ipywidgets とか何年も触ってないので、その辺は ChatGPT に聞きます。
ロジックと言えるロジックは API へのリクエストと音声データのロード部分なので、まずはそこをやっていきます。
TTS のサンプルを見ても、response.stream_to_file("output.mp3") みたいなのばっかりですが、ファイルには保存せずに直接プレイヤーにロードしたいので、まずはそのためにレスポンスの正体を見ていきます。
import os from openai import OpenAI os.environ["OPENAI_API_KEY"] = "sk-..." client = OpenAI() response = client.audio.speech.create( model="tts-1", input="こんにちは", voice="alloy", )
で実行して、response を見てみる。
>>> type(reseponse)
openai._base_client.HttpxBinaryResponseContent
なるほどなるほど。よくわからないので ChatGPT さんに聞いてみる。

これで再生できなかったので、その原因を聞いてみたところ seek(0) してないかもということで、やってみたら再生できた。
あとはパラメータ設定用のウィジェットを作っていって、配置すれば良いはず。

音声再生速度は HTML を埋め込まないとプレイヤー側では制御できないようで気に入らなかったので、OpenAI API の speed で制御することにする。

速度制御用のスライダー。
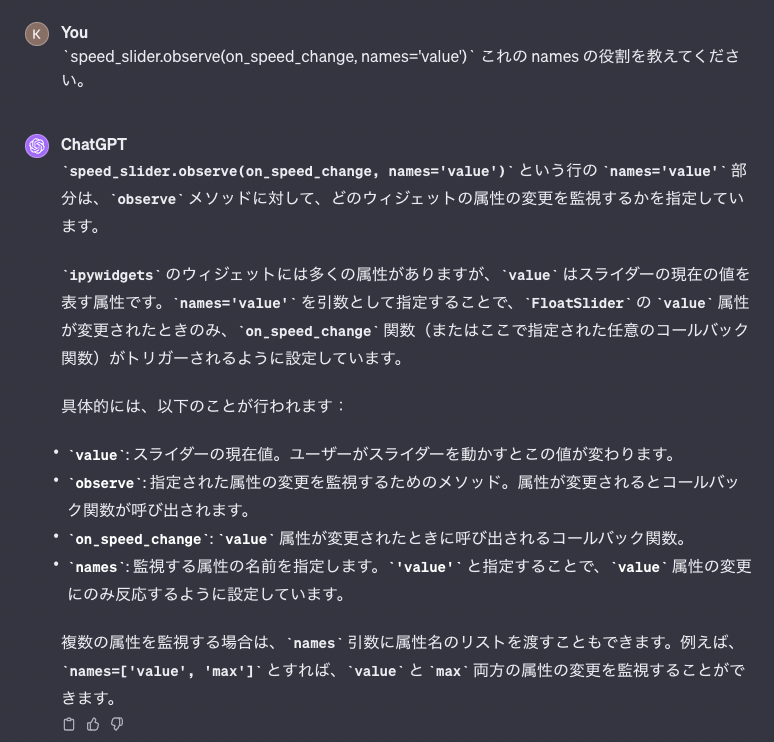
引数の意味も答えてくれる。

イベントハンドラーについて聞く。
ここまでできたので、適当にウィジェットの配置を考えて、こんな感じの画像にして、、、

投げた。

結果的に帰ってきたのは widgets.VBox([text, voice, speed, button, audio]) だったので、あんまり聞く必要はなかったかも。。。
レイアウトだけは何とかして欲しいので質問する。「各ウィジェットを中央に寄せられますか?」に対しては、
# VBoxを使ってウィジェットを中央に配置 box_layout = widgets.Layout(display='flex', flex_flow='column', align_items='center', # 中央揃え width='100%') # ウィジェットをVBoxにまとめる box = widgets.VBox([text, voice, speed, button], layout=box_layout)
と、いい感じに返してくれました。
最後に自分好みにコードを整形して、できたのがこちら。

想像通りのものができた!コードは記事の最後に掲載します。
個人的には "echo" の声が好きでした。
ということで、今回は開発というよりは実験・検証的な物作りでしたが、OpenAI の TTS を試す Jupyter Notebook を書いてみました。
こんな感じで、はじめは小さく、けど徐々にそれなりの規模を作っていければいいと思っています。
↓出来上がったコード↓
